
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 인증인가
- 코딩테스트파이썬
- Python
- 인터넷 네트워크
- 해시충돌
- 파이썬
- promise
- QuerySet
- JavaScript
- DP
- 파이썬문법
- 리스트컴프리헨션
- docker
- RESTfulAPI
- clone-coding
- 자바스크립트
- 알고리즘
- bcrypt
- 윈도우우분투듀얼부팅
- wecode
- 자료구조
- *args
- **kwargs
- django
- 백준
- decorator
- CSS
- 파이썬입출력
- 파이썬리스트컴프리헨션
- clone coding
- Today
- Total
개발기록장
[Python] BeautifulSoup4와 Selenium을 이용한 인스타그램 크롤링 및 이미지 다운로드 예제 본문
[Python] BeautifulSoup4와 Selenium을 이용한 인스타그램 크롤링 및 이미지 다운로드 예제
yangahh 2020. 12. 26. 20:09
파이썬 기본 문법 활용으로 인스타그램 크롤링을 해보았다.
beautifulsoup4과 selenium 라이브러리를 사용하여 인스타그램에서 검색한 이미지를 다운로드 하는 과정이다.
1. 준비
- chromedriver 설치
인터넷 브라우저를 제어할 수 있는 드라이버가 필요합니다. 저는 Chrome을 사용할 것이기 때문에 chromedriver를 설치했습니다.
chromedriver를 설치하려면 자신의 chrome과 맞는 버전을 설치해야하는데
chrome://version/ 에서 내 chrome의 현재 버전을 확인하실 수 있습니다.

아래 링크를 통해 자신의 chrome버전과 같은 chromedriver를 선택하고 내 os에 맞게 설치합니다.
chromedriver.chromium.org/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
chromedriver.chromium.org

** 설치를 한 후 윈도우의 경우 작업할 폴더에 chromdriver 파일을 넣어주셔야 합니다.
** 맥의 경우 homebrew로도 간단하게 설치 가능합니다.
=> brew install --cask chromedriver
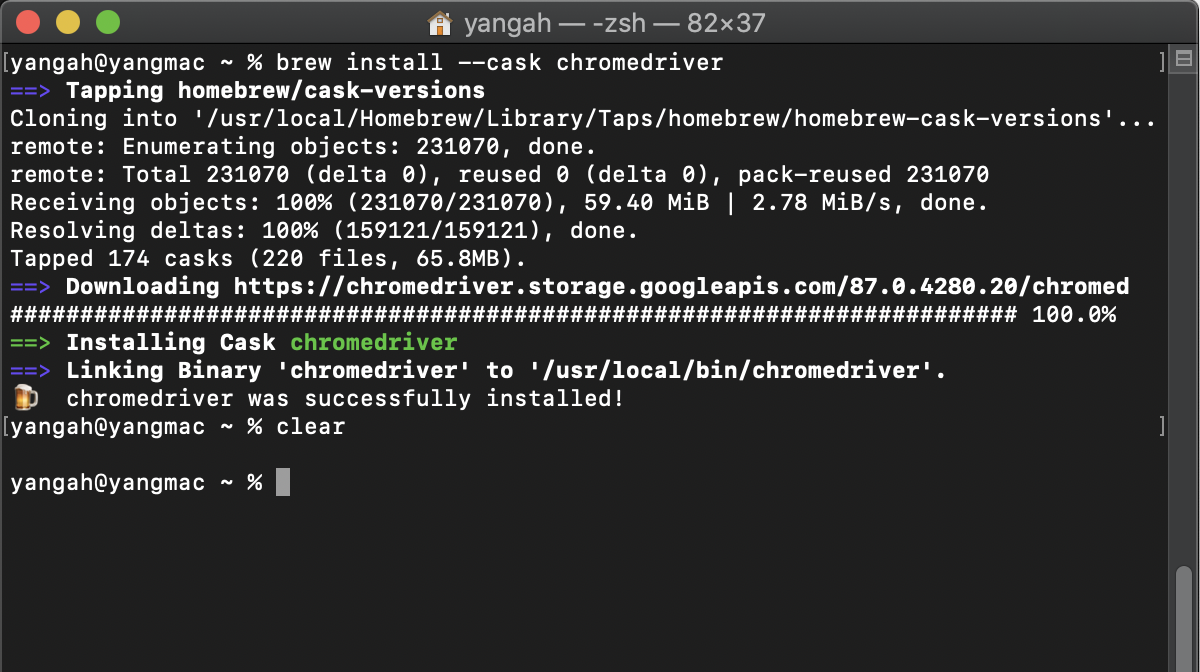
- Selenium 라이브러리 설치
Selenium을 사용하면 webdriver API를 통해 Chorme과 같은 브라우저를 쉽게 제어할 수 있습니다.
프로그래밍으로 브라우저 동작을 제어해서 마치 사람이 이용하는 것 같이 웹페이지를 요청하고 응답을 받아올 수 있기 때문에
동적으로 생성되는 사이트의 데이터를 크롤링 등의 자동화 업무를 수행할 때 매우 유용하게 사용되는 스크래핑 도구입니다.
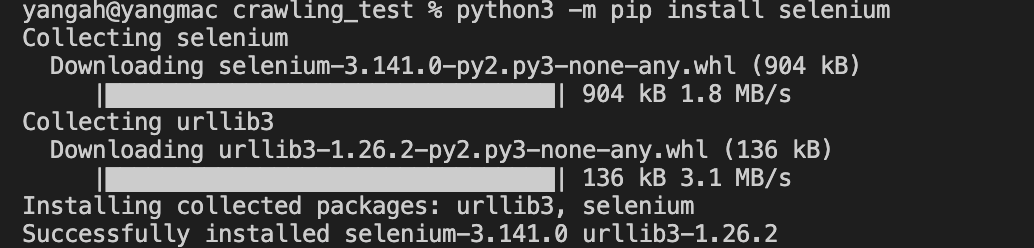
Selenium 설치는 간단합니다.
- 맥, 리눅스 >> python3 -m pip install selenium
- 윈도우 >> python -m pip install selenium
- Beautifulsoup4 라이브러리 설치
BeautifulSoup4는 HTML 및 XML 파일에서 원하는 데이터를 손쉽게 추출할 수 있도록 도와주는 파이썬 라이브러리 입니다.
BeautifulSoup4도 pip를 이용하여 설치해줍니다.
- 맥, 리눅스 >> python3 -m pip install beautifulsoup4
- 윈도우 >> python -m pip install beautifulsoup4

2. 코드 작성
from urllib.request import urlopen # urlopen 함수는 웹에서 얻은 데이터에 대한 객체를 반환해줍니다
from urllib.parse import quote_plus # 문자를 아스키코드로 변환하여 url에 넣기 위해
from bs4 import BeautifulSoup # beautifulsoup 사용
from selenium import webdriver # 웹드라이버 사용
from selenium.webdriver.common.keys import Keys # 웹에서 값을 입력해야할 때 사용
import time
import os # 이미지를 저장할 폴더를 생성할때 필요
# CERTIFICATE_VERIFY_FAILED 오류 해결
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 아이디, 패스워드 입력받기
# 인스타그램에서 검색을 하려면 반드시 로그인을 해야 사용가능하게끔 바꼈습니다..
# 자동화를 위해 코드에 id와 pw를 넣으면 좋지만 보안상 input을 이용해 입력을 받아 구현하였습니다.
id = input('instagram 아이디 및 계정 입력 : ')
pw = input('instagram 패스워드 입력 : ')
# 필요한 url설정
baseUrl = 'https://www.instagram.com/explore/tags/'
plusUrl = input("검색할 태그 입력 : ")
url = baseUrl + quote_plus(plusUrl) # quote_plus를 이용하여 아스키코드로 변환
# 이미지를 저장할 img 폴더 생성 (폴더가 없을때만 생성)
if not os.path.exists('./img'):
os.mkdir('./img')
# 브라우저 실행 및 인스타그램 로그인 화면 이동
driver = webdriver.Chrome()
driver.get('https://www.instagram.com/accounts/login/')
time.sleep(2) # 웹드라이버가 웹 페이지를 로딩하는데 걸리는 시간을 기다려주기 위해 (>> Selenium의 단점..)
# 로그인
id_input = driver.find_element_by_css_selector(
'#loginForm > div > div:nth-child(1) > div > label > input')
pw_input = driver.find_element_by_css_selector(
'#loginForm > div > div:nth-child(2) > div > label > input')
id_input.send_keys(id)
pw_input.send_keys(pw)
pw_input.submit()
time.sleep(4)
# 로그인 후 뜨는 팝업창 해결
save_late_button1 = driver.find_element_by_xpath(
'//*[@id="react-root"]/section/main/div/div/div/div/button')
save_late_button1.click()
driver.implicitly_wait(3)
save_late_button2 = driver.find_element_by_xpath(
'/html/body/div[4]/div/div/div/div[3]/button[2]')
save_late_button2.click()
# 검색 페이지로 이동
driver.get(url)
time.sleep(1)
# 드라이버로 페이지 소스를 가져와서 html 변수에 저장
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 검색된 모든 인스타 게시물 선택(아래 selector를 가지고 있는 것을 불러와서 저장)
posts = soup.select('.v1Nh3.kIKUG._bz0w') # 클래스가 여러개인 경우는 공백을 없애고 .으로 이어주기
# posts 변수에는 .v1Nh3.kIKUG._bz0w 이 selector를 가지고 있는 모든 태그들이 들어감.
# 각 게시물의 링크와 이미지 url가져오기
for index, post in enumerate(posts):
print('https://www.instagram.com/' + post.a['href'])
imgUrl = post.select_one('.KL4Bh').img['src']
with urlopen(imgUrl) as f: # imgUrl을 열어서 저장
# 저장한 imgUrl을 다시 열어서 이미지 파일로 파일 이름을 지정해서 저장
with open('./img/' + plusUrl + str(index) + '.jpg', 'wb') as h: # wb는 쓰기모드 + 바이너리모드. 이미지이기때문에 b모드를 써줘야한다.
image = f.read() # f를 읽어와서 img라는 변수 안에 저장
h.write(image) # 가져온 이미지를 해당 경로에 지정된 이름으로 저장
print(imgUrl)
print()
# 코드 실행 잠시 멈춤
time.sleep(2)
# 드라이버 종료
driver.quit()
** urlopen에서 SSL: CERTIFICATE_VERIFY_FAILED 에러 발생
Traceback (most recent call last):
File "/Users/yangah/Documents/Study/python/crawling_test/crawling_test.py", line 66, in <module>
with urlopen(imgUrl) as f: # imgUrl을 열어서 저장
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/urllib/request.py", line 214, in urlopen
return opener.open(url, data, timeout)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/urllib/request.py", line 517, in open
response = self._open(req, data)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/urllib/request.py", line 534, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/urllib/request.py", line 494, in _call_chain
result = func(*args)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/urllib/request.py", line 1385, in https_open
return self.do_open(http.client.HTTPSConnection, req,
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/urllib/request.py", line 1345, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1122)>구글링 결과로 아래 코드를 추가하여 해결할 수 있었다..
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
참고 : stackoverflow.com/questions/35569042/ssl-certificate-verify-failed-with-python3
SSL: CERTIFICATE_VERIFY_FAILED with Python3
I apologize if this is a silly question, but I have been trying to teach myself how to use BeautifulSoup so that I can create a few projects. I was following this link as a tutorial: https://www.y...
stackoverflow.com
3. 실행 결과

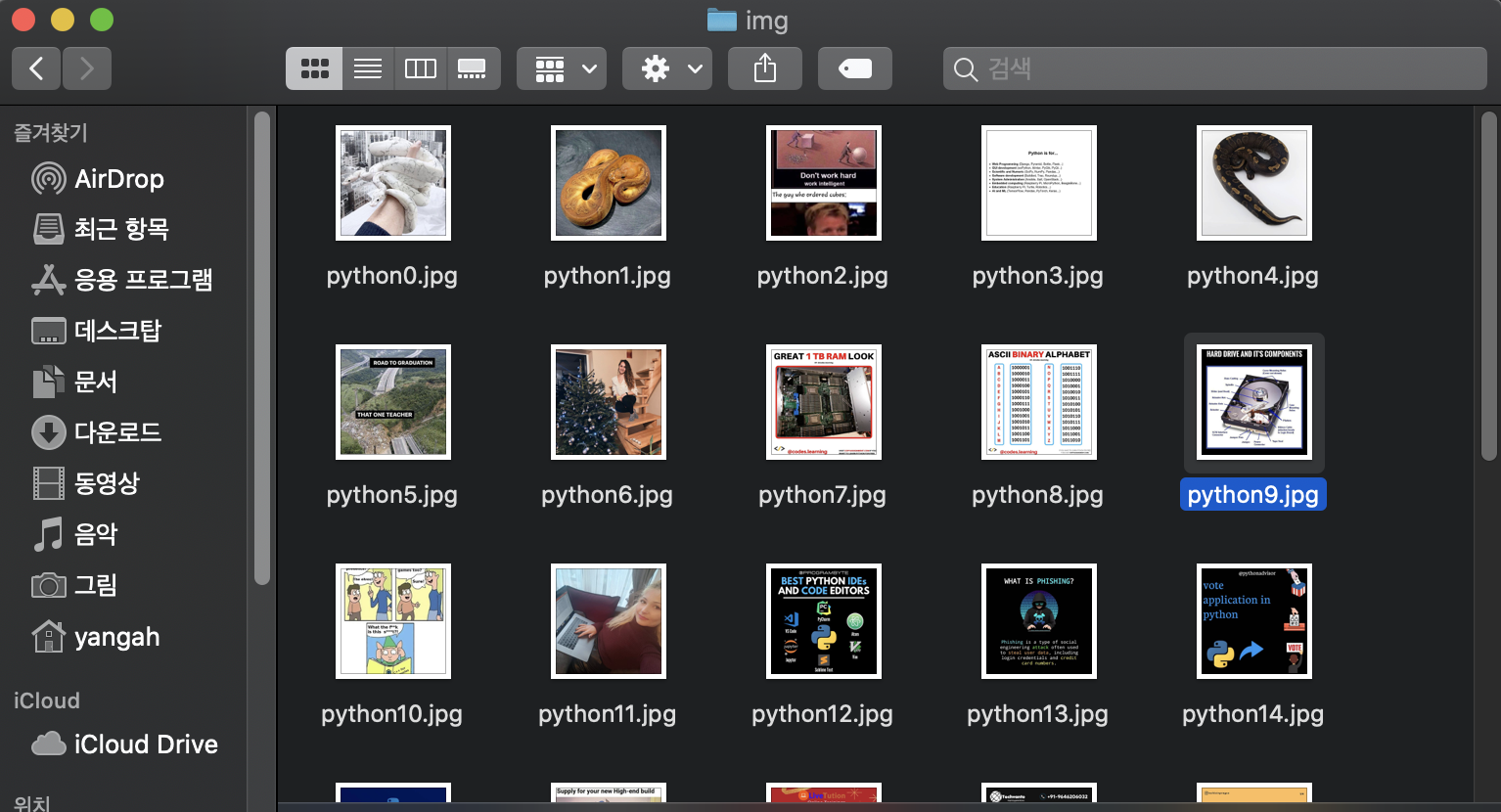
이미지를 다운받은 폴더에 가면 32개의 이미지들이 저장되어있는것을 확인할 수 있습니다.
32개인 이유는 현재 인스타그램에서 검색을 하면 한 페이지에 나오는 데이터가 32개이기 때문입니다.
더 많은 이미지를 저장하고 싶다면 selenium에서 제공하는 스크롤을 원하는 만큼해서 더 많은 데이터를 가져올 수 있습니다.
예시)
# 스크롤 횟수 지정 예시
scroll_cnt = int(input("스크롤 횟수 : "))
for i in range(scroll_cnt):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
time.sleep(3)
# 드라이버로 페이지 소스를 가져와서 html 변수에 저장
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
## 생략..
'TIL > Python' 카테고리의 다른 글
| [Python] 파이썬 모듈과 패키지(2) - 절대경로와 상대경로 + ImportError (0) | 2021.01.16 |
|---|---|
| [Python] 파이썬 모듈과 패키지(1) - 개념 (0) | 2021.01.16 |
| [Python] 가변 인수와 가변 키워드 인수 + 파라미터 순서 (0) | 2021.01.14 |
| [Python] Argument 설정에 따른 함수 호출과 default value parameter (0) | 2021.01.14 |
| [Python3] 파이썬 완전 기본 문법 정리 (데이터 타입, 입출력, 연산자) (0) | 2021.01.13 |



